 Teaser
TeaserAbstract
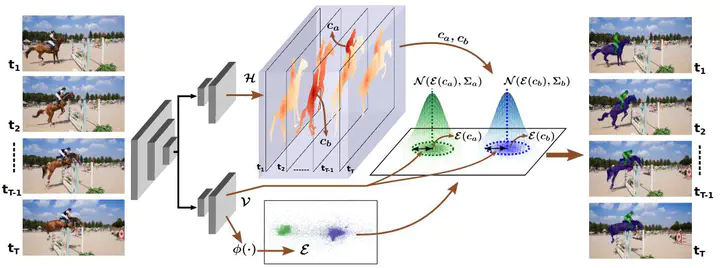
The task of Video Instance Segmentation (VIS) involves segmenting, tracking and classifying all object instances present in a given video clip. Occluded VIS is a more challenging extension of this task which involves longer video sequences where objects undergo significant occlusions over time. Most existing approaches to VIS involve multiple networks which separately handle segmenting, tracking and classifying object instances, and potentially a set of heuristics to combine the individual network outputs. By contrast, we employ just one, single-stage network without any heuristics or post-processing for the end-to-end task. Our approach is called ’STEm-Seg’, which is a bottomup method for Segmenting object instances in videos using Spatio-Temporal Embeddings. We achieve 3rd place in the Occluded VIS challenge with an mAP score of 21.6% on the test set.